The problem is that the majority of these companies are created for customer sales, whereas B2B needs different specifications. We evaluated the market and made the list of the top B2B Shopify development companies within the United States.
The report provides evidence instead of publicity. Certifications, platform qualifications, executed projects, and teams that know how to manage complex catalogues and multiple business units. You will also see where each company is open to different engagement models, meaning that you can bring on B2B Shopify experts for either a migration or a long runway without being forced to work under strict contracts.
What Makes a Good B2B Agency
A proficient B2B agency considers itself a strategic partner rather than merely a supplier. It comprehends intricate purchasing processes, various influencers, and eventual customers worth over years’ time, and shows it in user experience that is easy to understand, architecture that is solid, and connections that are seamless with the company’s CRM, ERP, and PIM systems. The strategy is to make it very easy and smooth for repeat customers rather than just following the latest surface-level trends.
In addition to that, the best B2B agencies are very disciplined in their execution. They define the project scope in a practical way, use the language of business to communicate, and then create systems that allow for growth without the need for constant reworking.
Top Shopify B2B Agencies
A few B2B eCommerce solutions are designed with endless composable stacks for agility, having the possibility to change them any way you like. Others prefer combining ERP and CRM technologies into one framework for better stability. The correct choice is contingent upon the way your firm operates.
Does it manage all the things like complicated pricing, account hierarchies, quote workflows, and multichannel sales effortlessly and without extensive customizations? How well does it deal with the increased traffic, product data, and order volume? What about the uptime record and infrastructure of the CDN?
Stellar Soft
Stellar Soft is an agency that offers complete software development and eCommerce engineering services having the main objective of creating digital products that are scalable and ROI-driven. The team takes part in the whole delivery process, starting from discovery and system architecture to development and long-term support, which means that every solution is guaranteed to be both reliable and capable of growing in accordance with the business.
The agency mainly deals with developing Shopify and Shopify Plus, creating custom software, providing Magento solutions, and doing eCommerce website design from scratch to finish. Stellar Soft is there to assist with the launching of new products, complicated changes in platform, and development of custom features, which include migrations, headless commerce, frontend and backend extension, and integration with third-party services.
Electric Eye
Electric Eye, a Shopify-focused design and development studio established in 2016, is proficient in helping eCommerce brands to enhance their online presence through creative design, development, and optimization strategies. The company offers a wide range of services within Shopify, including but not limited to custom themes, store redesigns, migrations, app integrations, and more.
Amasty
Amasty is a leading development company and product vendor that specializes in the Magento platform and is recognized for its impressive range of Adobe Commerce extensions as well as large-scale customizations. The firm focuses on making Magento stores better through various means like improving speed, making the checkout and catalog more sophisticated, adding B2B features and integrating third parties’ systems that are very complex.
Quickfire Digital
Quickfire Digital is among the UK’s fastest-growing Shopify Plus B2B specialists, providing high-performance constructions and active growth retainers. The agency relies on speed, clear code, and a method that includes CRO in the sprints instead of postponing it as a later step. This method allows brands to become operational sooner and grow without recording.
Cake Agency
Cake Agency was also established in the United Kingdom. It is an eCommerce agency that is made by the retailers for the retailers and focuses on the strategy, development, and business growth services of Shopify. The agency’s main strength is in building and migrating on Shopify Plus, and providing customer development, marketing, and branding, and consultancy tailored to DTC and B2C brands that are ambitious.
Charle Agency
Charle is a small company which has a London team that developed over 150 Shopify stores and generated millions of GMV. The output was the result of a very close collaboration between creative and B2B Shopify experts and the use of data-driven decisions that made CRO part of the design process instead of treating it as an afterthought. Charle’s approach is very fruitful for consumer brands with high ambitions that want to take their wholesale and e-commerce arms to the next level.
Choosing the Right Shopify B2B Agency
Choosing a Shopify B2B agency is no longer a question of brand names but rather an issue of operational fit. The perfect partner knows exactly how your business works in terms of sales, how the buyers do their reordering, and how the flow of data is between commerce. Seek teams that start asking architectural questions from the very beginning. Track:
- Operational alignment. Proven experience with B2B buying flows, repeat orders, account hierarchies, and complex pricing logic.
- Systems thinking. Clear understanding of how Shopify integrates with ERP, CRM, PIM, and logistics without fragile workarounds.
- Architectural maturity. Ability to ask hard questions early, validate assumptions, and design for scale rather than quick fixes.
- Delivery discipline. Transparent scoping, realistic timelines, and predictable execution across discovery, build, and launch.
Transparent scoping, achievable timelines, and the ability to back both project-based and long-term engagement models mitigates execution risk. Moreover, a loyal partner will assist you in making trade-offs consciously rather than over-promising features that create complexity without any measurable return.
Final Thoughts
The use of SaaS-first Shopify builds helps in getting the project going quickly but B2B victory entails depth: system integration, pushing the limits of performance, and creating workflows based on buyers’ needs. The Shopify B2B agencies in the USA mentioned in this article are the ones that do not merely implement on the surface but seriously consider the logistics of eCommerce as business infrastructure.
Stellar Soft’s services are where the strategy, engineering, and measurable ROI meet if your B2B commerce project does not only require configuration. The areas that Stellar Soft covers are wide and they include Shopify Plus B2B orientation, headless commerce, custom backend extensions, and ERP integrations which together build B2B systems that are scalable and designed for long-term growth, not short-term launches.
FAQs
What makes Shopify B2B development different from D2C?
B2B Shopify projects require account-based pricing, approvals, ERP integrations, and workflows optimized for repeat buyers rather than one-time checkouts.
Is Shopify Plus necessary for B2B eCommerce?
Shopify Plus is often required for advanced B2B features, higher API limits, automation, and multi-store or multi-region setups.
Can Shopify handle complex B2B pricing and catalogs?
Yes, but complex pricing, contracts, and catalogs usually require custom development, apps, or headless extensions.
How do B2B agencies integrate Shopify with ERP and CRM systems?
Experienced Shopify B2B agencies in the USA use custom APIs, middleware, or event-driven integrations to sync orders, customers, inventory, and pricing reliably.
When should a business move from a basic Shopify setup to a B2B-focused agency?
Once manual processes, pricing exceptions, or system limitations start slowing sales or operations, a specialized B2B agency becomes critical.
However, an online commerce project requires one to first understand the main requirements for creating and maintaining a digital store. A wrongly made requirements list could result in a project with missing features or even not working at all.
What should I do to present an eCommerce website containing the right functional and non-functional eCommerce website requirements? Get the eCommerce checklist along with the straightforward tips here!.
Functional Requirements for an eCommerce Store
Functional online store requirements can be understood as the user’s view of what they can see and how the website will interact with them. Hence, these are the specifications for the different features of your store. For instance, you might want to implement a feature that would send an email to the customers confirming their order post-purchase. This feature is included in the development process according to the eCommerce functional requirements.
You will easily check off the eCommerce website requirements listed below if you are planning a new site, or if you wish to improve an existing one by making it richer with new functionalities.
Content Management System
The content management system (CMS) you select will be the major factor for your eCommerce possibilities and its flexibility. Furthermore, if you intend to develop an online store with WooCommerce, then you need to think of the hosting company and get the best theme and plugins that cater to your requirements.
Conversely, if you select Shopify, the door swings wide open to numerous ready-made tools that would make life easier for the sellers. The eCommerce store will be able to use the range of responsive templates from Shopify, giving it the highest level of adaptability. This enables the website to take on a nickname that is in line with the brand image. The two platforms also provide the option to create blogs, which can be a source of more traffic to the store and also have content management access for the admin of the website.
Product Catalog
Once you have selected a platform for your business, think about additional eCommerce functions that will be necessary for arranging your products. The establishment of product categories is to be made, and the website administrators should be given the right to add, remove, and modify products in the catalogue. Moreover, every product needs to have its own unique page with a brief and detailed description, pictures, properties, price, and stock.
Search and Filtering
A place on your site has to be designated for a search bar to look for a specific product using the keywords, name, and category. Also, to ease the search, allow filtering features to work on price, brand, colour, size, and other relevant factors. Moreover, a better customer experience is created by allowing sorting of products based on price, popularity, ratings, and more.
Shopping Cart
Online shopping carts must be created in such a way that shoppers can easily put items into the basket and check the product quantities, their prices, and the total cost. Customers ought to be allowed to make their shopping carts more specific by taking out or putting in items, and even by emptying the whole cart. One of the optional features for an online shopping site that helps ina good customer experience is the Save for Later option that lets customers keep things for further purchases.
Checkout Process
In order to obtain the highest conversion rate, you have to make your checkout process as easy as possible. A purchase form should be designed for its usability; absolutely nothing should be able to block or mislead the users in this journey. One of the best tips for an eCommerce site is to provide a guest checkout, which gives customers the option of buying without having to sign in.
Besides, you would need to cater to many different payment options, like credit and debit cards, PayPal, Google and Apple Pay, etc. With various shipping methods, including fast and free shipping, the customer has more power over their order. Do not forget to include a section for the shipping address. Give your customers a chance to check their order before they pay, and after the transaction is done, send them a confirmation either by email or SMS.
Order Management
The users are to have the option to monitor the progress of their orders at every stage: processing, shipping, and delivery. You are to give them the right to view their past orders and even place new orders based on those. Furthermore, the order management system will let users cancel their orders prior to shipping, and also request returns and exchanges.
Inventory Management
Your system ought to refresh product availability on its own according to stock levels, and when stocks drop, an administrator should be informed. Besides that, you will need an inventory control feature for multiple locations (like warehouses and retail stores).
Product Reviews and Ratings
Social proof gives customers the assurance they need to make their purchases. It appears in three ways: ratings, reviews, and testimonies. Ratings and reviews are obvious; they give the visitors of the site the possibility of understanding how other buyers think about the products and services before they decide to purchase.
The value of testimonials lies in the fact that they are not grounded on numbers or facts but rather an endorser client who might sound more genuine than the praises from regular people.
Put a review option on your product detail page and give buyers the chance to share their opinions about the purchase. The moderators in charge of your site should be able to oversee the reviews and take down any if necessary.
Technical & Legal Requirements
The regulations governing online store requirements serve as a shield to both clients and companies. They regulate the issues of privacy regarding personal data, security of financial transactions, and the moral practices of corporations.
Choose the Right Business Structure
Even though the law does not necessitate business registration, it is still a wise move to safeguard your enterprise. Talking to an attorney can help you decide which option is most suitable for your situation.
- Sole proprietorship. If you do not incorporate, your business will be treated as a sole proprietorship by default. It is a less formal option with fewer paperwork, but it does not provide personal responsibility protection.
- Limited liability company (LLC). Registering as an LLC gives you personal liability protection and tax flexibility.
- Corporation. Large businesses are often registered as companies. Corporations offer shareholder options and provide significant legal protection.
Sometimes you might need a business license to operate legally in certain situations. Mostly, this applies to certain types of businesses like alcohol and agriculture, which are under special regulations. If you are going to set up a reseller business, a certain license may be required from you as well.
Understand Tax Obligations
Tax laws for sales vary across states and some specific countries. They make it easier when you understand the laws properly so that you can tell the customer when and how you are really passing the taxes to them, and when the tax liability will be yours. Such knowledge of laws helps you in selling the products at a certain price and still making a profit on every sale.
Besides, keeping tabs on tax dates for businesses will also be necessary. Business taxes are different from personal taxes; for example, some states require companies to pay taxes every three months.
Consider Business Insurance
In case you have workers, it is likely that you will have to lay out money for workers’ compensation, unemployment, and disability insurance. All of these are meant to secure both the employees and the company in case of an accident, such as injury at work.
Insurance is not always a must in business, especially if there are no employees, but many times it is a wise decision. A large number of online retail sellers also prefer to take out insurance policies that are for both property damage and liability claims.
To understand more, property damage insurance covers warehouses, and any physical property, such as office spaces, stocked with the products that are used by the company and also includes retail business, if you have one. On the other hand, liability insurance policies pay for any possible legal fees related to any lawsuits which your company might encounter.
Store UX Checklist
Conceiving a Shopify store that is able to yield sales is first and foremost a matter of skeleton and usability, not ornamentation. The use of a responsive theme guarantees that your store is always functioning the same way, no matter what device is being used, which is very important because mobile gets a big share of the eCommerce traffic.
| Step | What to do | Why it matters | Impact on sales |
| Choose a responsive theme | Select a theme that adapts to all devices | Ensures consistent UX on mobile, tablet, and desktop | Higher engagement, lower bounce rates |
| Adjust colours, fonts, and layout | Optimise for mobile | Aligns store with brand identity | Builds recognition and trust |
| Create an engaging homepage | Simplify menus, compress images | Improves speed and usability on phones | Better mobile conversions |
| Add essential pages | About, Contact, FAQ, Shipping | Builds transparency and trust | Reduces hesitation before purchase |
| Use high-quality images | Professional product visuals | Enhances perceived product value | Increases conversion rates |
| Create engaging homepage | Clear messaging and structure | Guides first-time visitors | Stronger first impressions |
| Set clear navigation | Logical categories and menus | Helps users find products quickly | Faster path to checkout |
| Add breadcrumb navigation | Visible page trail | Improves usability and orientation | Lower drop-off rates |
| Add trust badges & reviews | SSL, payments, testimonials | Reduces perceived risk | Higher checkout completion |
| Create a blog section | Educational, product-related content | Supports SEO and authority | Long-term traffic and sales growth |
Store users are less likely to experience uncertainty and are more inclined to navigate the store confidently if the essential pages, intuitive navigation, breadcrumb trails, and visible trust badges are present. The store’s products are presented professionally through high-quality images and a lively homepage, and customer reviews add to the store’s trustworthiness.
Final Thoughts
Starting an online shop without an organised checklist of eCommerce website requirements adds up technical debt, puts the business at greater legal risk, and loses sales. Well-defined functional, technical, and UX requirements not only set the path for business goals but also ensure the possibility of scalability from the very first day.
Stellar Soft works with companies to create, construct, and execute an eCommerce launch that complies with all functional, legal, and UX requirements of the real world. Gaps are prevented from turning into expenses. Consult with Stellar Soft and get your eCommerce checklist ready for a store that is up and running.
FAQs
What are functional requirements in eCommerce?
They define how the store works, including product listings, checkout, payments, and order management.
Why are non-functional requirements important?
They ensure performance, security, scalability, and legal compliance as traffic grows.
Which platform is better for starting an eCommerce store?
Shopify suits fast launches with built-in features, while WooCommerce offers deeper customization with more setup effort.
How many payment methods should an eCommerce store offer?
At minimum, cards and one digital wallet; more options reduce checkout abandonment.
A bad user experience causes customers to leave without buying and results in the loss of sales, while the view of the customers changed by a systematic and user-centered approach can be through the conversion of customers into loyal ones.
This book aims at the Shopify brands that desire to grow, increase sales and get bigger. We will uncover the design ideas that impact customer behavior and purchasing decisions directly. Forget about theoretical advice; this is a blueprint full of efficient and fast actions that will create a mobile first eCommerce experience that is not only visually appealing but also has a high conversion rate.
What is Mobile-First eCommerce?
A mobile first eCommerce strategy is a website creation approach that puts desktop second and mobile first in the order of things to develop for. This strategy has come up several years back in order to resolve the main pain point of the users. It was that users wanted to have the same functionalities on their smartphones as on their desktop computers. By this technique, users’ pains are lessened by making a mobile version first without losing content or functionalities.
This is a web designer’s work as he will first design the site for mobile devices and then upgrade it for desktop use. This is the opposite of a desktop-first approach, which involves creating a website, removing the parts that are not compatible, and finally producing a mobile site.
One of the benefits of mobile-first design is that it allows companies to have more direct and appropriate conversations with their customers. It goes as far as using mobile-specific technologies like GPS and built-in cameras to create features that are simply not there for desktop users.
Mobile-First Design vs Responsive Design
Mobile-first design is not the same as responsive eCommerce design. Responsive design modifies the layout of a website according to the different screens. Mobile-first design starts with the mobile content and then gradually increases to larger displays. Their approach is the main difference.
A majority of online shoppers are using mobile devices, so mobile-first design is very important for the success of the site. The strategy makes it easy for the users to shop on the small displays which are now the standard. It’s about creating a website that is friendly to mobile users. Responsive eCommerce design provides flexibility.
| Design aspect | Mobile-first design | Responsive design |
| Core approach | Content and functionality are designed for mobile first, then enhanced for larger screens | A single layout adapts fluidly to different screen sizes |
| Primary focus | Mobile usability, speed, and content priority | Visual flexibility across devices |
| Design process | Starts with the smallest screen and scales up | Often starts with desktop and scales down |
| Content strategy | Essential content only, added progressively | Same content rearranged depending on screen size |
| Performance impact | Typically faster on mobile due to lighter initial load | Can be heavier if desktop assets load on mobile |
| Mobile UX eCommerce philosophy | Mobile is the default user experience | Device-agnostic experience |
| Best use case | Mobile-dominant audiences and eCommerce stores | Broad audiences with mixed device usage |
| Risk if misused | Desktop experience may feel minimal | Mobile experience can feel compressed or cluttered |
The principles of mobile-first design consist of ease, transparency, and movement. By emphasizing these elements, companies will not only improve the visual appeal of their m-commerce platforms but also increase its usability. Key features are rapid-navigation, concise text, and picture loading speed.
Benefits of Going Mobile-First
One of the greatest advantages of mobile-first design is that it can avoid the problems often associated with less accessible desktop-first approaches. In case your organization is still resistant to adopting a mobile-first strategy, consider the following five reasons that may change your mind.
Responsive for All Platforms
The major advantage of mobile-first approach is that your site is convenient for all platforms. The site that smartphone users access should be the same as the one that users on desktop computers see.
Information is More Manageable
Mobile sites are very dependent on content. There is no room for unimportant things, and hence the limited area should only be occupied with content that will guide the customers through the purchasing process. The text is also much easier to read on mobile phones as the writers usually divide it into two or three sentence paragraphs.
Search Engine Optimization Thrives
A major factor behind a website’s SEO grade is adaptive mobile design. Presently, the most popular search engines like Google are practicing mobile-first indexing policies. It implies that not having a mobile-friendly site will cause you to drop in search listings and consequently, lose potential customers.
Less Code Means Fewer Bugs
A mobile-first coding strategy means that the very first steps of a website are done with the simpler code intended for mobile devices. On the other hand, the desktop-first strategy does the opposite. It writes the complicated desktop code first and then gives the smaller screens overrides. When you code for mobile first, it simplifies your code and reduces the chance of errors in the future.
User Experience (UX) is Top-Notch
Mobile UX eCommerce is undoubtedly one of the major aspects to consider. Improving the experience of your visitors means that you will not only earn their loyalty but also have them as repeat customers. On the contrary, if a website is extremely sluggish or hard to use, the users will abandon it in no time.
Mobile-First eCommerce Best Practices
It is a must for all websites to get a good position in Google’s search results. It’s a fact that you know, your client knows and online buyers by their regular preference for high-ranking websites prove it. So, whether you are starting a blog, a portfolio, or an online store, it is a competition to reach the top, thus, you have to optimize your client’s site right from the beginning.
1. Make Sure Your Site is Fast
In terms of mobile optimization, speed is the first (and maybe the most important) factor.53% of the users coming to a website expect an eCommerce site to be fully loaded in three seconds or less. Moreover, give or take, one out of two online shoppers will cancel their order if the website they are visiting takes too long.
We look at internet transactions as something that should happen immediately, or almost immediately. The performance of the website has to be very good considering that we are no longer talking about the dial-up connection. These statistics cover all website visits, be it mobile or desktop. It is fair to say that the users’ expectations are rather low on mobile where convenience is the main factor.
2. Optimize Your images
Large image files are among the most common culprits that slow down website performance. If your site is slow, start at this point.
Consider using a plugin or software to decrease the size of your image files, along with a CDN and lazy loading for further enhancement of speed.
Furthermore, it is essential to select the correct image formats. Mobile devices can benefit from WebP images which have a file size that is 25-34% smaller than JPGs.
3. Use Space Effectively
In the case of a smaller screen, use of space is of utmost importance. Poorly designed mobile interfaces often make one of two mistakes. Either they attempt to squeeze a lot of data into the site, resulting in a messy and crowded UI on the smaller screen or they take the opposite approach and leave large areas of empty space, which are noticeable on a small screen.
You need to find that sweet spot between too much and too little white space. There is sufficient space to allow the design to be alive without distracting the user from the content.
Space is of great importance even more so around clickable items. Misclicks can be very irritating. You meant to click on a certain button or object but inadvertently clicked on another and ended up in a different section than you intended. An error can be so vexing that the user decides to leave your website for good.
4. Enable Touch Interactions
Embracing the factors of mobile touch screens is very important. The users’ touch screen experience is entirely different from that of mouse and keyboard. So, consider these differences in your mobile user interface design. Switch between images with a swipe. Use pinch and double-tap gestures for zooming in on product images.
One more point in favor of tappable elements is the feedback like giving a slight vibration to the user as a signal during the press of an interactive component, like a call to action button). Conversely, wipe off the actions that do not fit well on a touchscreen, like hover animations, and cover them with an action that is more mobile device-friendly.
5. Make Important Pages Easy to Reach
The site must be easy and obvious in terms of navigation, the essential components such as the home page, user account, and cart, checkout are to be obviously and easily accessible.
The more you force clients to ponder where to find these parts, the more you will lose them. This might be fatal. If a customer has already put items in his cart and is ready to pay, smoothen the path for him.
6. Minimize and Optimize Text Inputs
Mobile typing takes a lot of time, so try not to use text inputs wherever possible. Some areas may require text inputs, so allow autocomplete and auto-suggestion to speed the process up and make it easier.
Moreover, customize the keyboard to the type of input and make text inputs less difficult. If the input is for a number, like a phone number or credit card info, show a numeric keypad so the user can finish the input faster and more instinctively.
7. Simplify the Checkout Process
It is a very effective way to improve mobile user experience to get rid of the friction during the checkout process. The check out process is more complex and boring on mobile which probably causes the average mobile conversion rate to be 50% of that of desktop eCommerce sites.
How can we make it easier? One way is reducing text entry requirements. Let users create an account and store their data but do not ask for excessive data – or at the very least make these fields optional.
Final Thoughts
Mobile-first eCommerce development is not an optimization choice anymore, it has become a structural requirement for modern online stores. With mobile traffic dominating search, discovery, and purchases, designing for small screens first forces clarity in content, performance, and navigation. Stores that treat mobile as the default experience consistently outperform those that adapt to it as an afterthought.
At Stellar Soft, we design and build mobile eCommerce platforms that load faster, convert better, and scale without friction. If your store needs to meet modern buyer expectations (and Google’s mobile-first standards) our team can architect, optimize, and future-proof it from day
FAQs
Is mobile-first better than responsive for eCommerce?
Yes, mobile-first prioritizes performance and usability where most purchases now happen.
Does mobile-first design improve SEO?
Yes, it aligns directly with Google’s mobile-first indexing and ranking signals.
Will mobile-first hurt desktop UX?
No, when mobile UX eCommerce is done correctly, desktop experiences are enhanced progressively without losing functionality.
Is mobile-first more expensive to build?
Not long-term, simpler codebases reduce bugs, maintenance, and performance costs over time.
One of the ways to set your online store apart is selecting the right Shopify theme. The best Shopify B2B themes come with features such as advanced product filtering and wholesale pricing that are specifically designed for the business’s needs.
A theme supporting your brand and providing a smooth user experience can help you create a professional and good-looking eCommerce site that communicates trust and confidence to your potential customers. An appropriate theme can make your B2B store visible, present the products in an excellent manner, and eventually lead to more sales and leads.
We will point out the best Shopify themes in this post. We will elaborate on how the best Shopify B2B themes can elevate your eCommerce site to the next level.
What Are B2B Shopify Themes?
Shopify B2B themes are the planned blueprints that characterize both the look and the usability of the online store created on the Shopify platform. They structure the visual layout, design elements, and the features of the website. Shopify offers an extensive selection of themes with different styles, degrees of customization, and compatibility with all kinds of businesses and marketplaces.
Themes are file collections that make a significant difference to the overall appearance and ambiance of an online shop. The core files of a theme include HTML, CSS, and JavaScript which collectively determine the site’s layout, visuals, and overall user experience. A theme can be a retail form for a brand’s identity and be a business tool by being unique for the particular brand or business.
Businessmen are given the liberty to select from assorted colors, fonts, images, and layout when they use Shopify wholesale themes. Apart from these, there are options to add panels such as navigation menus, product galleries, promotional banners, user reviews, etc. Themes can also be customized with the help of Shopify apps or by simply writing some code for the purpose.
Advantages of B2B Shopify Themes
B2B Shopify themes are designed mainly for the transaction and business-to-business sales. So, these themes also have a lot of features mainly for B2B eCommerce. Let’s start with the point of B2B eCommerce themes advantages:
1. Professional and Trustworthy Appearance
Shopify B2B themes often exude a very sophisticated and refined appearance that gives a strong sense of security and reliability to the customers for whom these themes are intended. They offer a flawless and orderly setup, the greatest typography, and the most elegant color combinations to present an authoritative image.
2. Customization Options
Shopify’s B2B themes present significant possibilities for customization to align with a brand’s image and create a unique online presence. The shopkeep can modify the theme’s colors, fonts, layouts, and other design elements according to his brand and give a consistent visual experience for his B2B customers.
3. Responsive and Mobile-Friendly Design
Shopify B2B themes are designed to be responsive, which, in essence, means that they adapt to different types of screen sizes and devices. As a result, the online store maintains its proper appearance and functionality on desktops, laptops, tablets, and smartphones. A mobile-friendly design is very important for B2B companies as their customers often use mobile devices for browsing and placing orders.
4. Integration with B2B Features
B2B Shopify themes often come with important B2B eCommerce apps’ built-in features or compatibility. Among these capabilities are customer-specific pricing, wholesale pricing, bulk ordering, quote request, tiered pricing, customized catalogs, and more. The integration with B2B apps removes the complexities of B2B transactions. It provides an uninterrupted buying experience to business customers.
5. Enhanced Product Catalogs
Shopify wholesale themes come equipped with sophisticated product catalog functionalities for handling extensive and intricate stock. They offer functionalities like product classification, variant and option creation, SKU and stock level management, and rich product information display. This creates an opportunity for B2B companies to introduce their products in an appealing manner, to give accurate price signals and to make ordering by customers smooth.
6. Secure and Scalable Infrastructure
Shopify guarantees a secure and trustworthy framework for online sellers, among which are B2B companies. By regular security updates, automatic backups, and compliance with PCI standards, Shopify protects important business and customer data. In addition, the scalable infrastructure of Shopify allows B2B companies to experience increased website visitors, to add more products to their inventory and to process large volumes of transactions without affecting the performance level.
7. Streamlined Checkout Process
Shopify B2B themes help to create a more seamless checkout process which results in less friction and ultimately a better shopping experience for business customers. These themes also include options like guest checkout, address recall, quick restocking, and payment among others. Having a hassle-free and effective checkout is very important for B2B transactions since it enables companies to complete their purchases with no hassle.
To sum up, Shopify B2B themes have a lot of features that are only for B2B eCommerce. They give businesses a choice of professional design, customization options, B2B feature integration, responsive and mobile-friendly layouts, and secure infrastructure with simple checkout processes. All these things will help the B2B company to be visible online, make the user experience better, get the customers’ loyalty, and make the transactions smooth.
Theme Comparison
Selecting the most suitable B2B Shopify theme isn’t a matter of looks but rather the theme’s structure, scalability, and ability to support complex purchase journeys. Though Expanse, Forge, Pursuit, and Sahara give good bases, they differ in terms of accessibility, catalog width, storytelling, configurability, and brand image, which are key when creating for wholesale customers, distributors, or high-value B2B buyers.
| Theme | Developer | Design character | B2B strengths | Customization & layout | Best fit for |
| Expanse | Archetype Themes | Clean, modern, content-forward | Excellent for large catalogs, detailed product data, scalable navigation | Highly modular sections, multiple layouts, strong content controls | B2B brands with large inventories, complex product hierarchies, or wholesale catalogs |
| Forge | We Are Underground | Bold, polished, conversion-driven | Strong visual hierarchy, supports credibility and trust for B2B buyers | Flexible layouts, deep customization, conversion-focused components | Industrial, manufacturing, or premium B2B brands that want impact and authority |
| Pursuit | Mile High Themes | Dynamic, contemporary, streamlined | Clear UX, intuitive flows for considered purchases | Custom sections, responsive layouts, straightforward configuration | Growing B2B brands balancing storytelling with usability |
| Sahara | DigiFist Shopify | Expressive, immersive, brand-led | Strong emotional engagement, good for differentiation-heavy B2B | Visual customization, creative layouts, design-forward sections | Design-led B2B brands where brand perception is as important as function |
Expanse is the most operationally robust for scale and catalog complexity in the B2B sector, while Forge has the advantage of being able to project authority and professionalism effectively. The Pursuit is also a very balanced solution, providing clarity and flexibility to companies at the growth stage, while Sahara is a perfect match for brands that rely on visual appeal and storytelling. The decision on which one to use is dependent on whether your main concern is depth, conversion rigor, usability, or brand impact.
Canopy
The Clean Canvas Canopy Shopify theme is nothing short of a fashionable and exquisite eCommerce theme that radiates business-like quality. The neatness of Canopy’s layout along with its detailing still further guarantees a straightforward and completely engaging experience for your buyers. Apart from this, there are also numerous ways to modify the theme according to the company’s needs which results in an even greater fit with the brand identity.
Expanse
The Expanse Shopify theme from Archetype Themes is a multi-purpose and powerful eCommerce theme that will give your online store a unique presence. Expanse with its modern and classy design makes the visual part of the customers’ buying experience quite appealing. The theme comes with state-of-the-art features such as section-wise customization, mobile-friendly design, and smooth integration with Shopify’s functions.
Forge
The Forge Shopify theme created by We Are Underground is a powerful and adaptable eCommerce theme that will take your online store to the next level. The modern and elegant design of Forge brings your customers a welcoming and engaging buying experience through their eyes. The theme boasts state-of-the-art functionalities like personalizable parts, resizable designs, and smooth connection to Shopify’s powers.
Pursuit
The Pursuit Shopify theme from Mile High Themes is a lively and interesting eCommerce solution perfect for you to expand your online store. It has a modern and splendid design that makes it easier and more enjoyable for your customers to buy. The advanced features of the Pursuit, like the ability to customize sections, responsive design, and smooth integration with the Shopify platform, allow you to make a distinctive and powerful store that is in line with your brand identity.
Sahara
Sahara is an eCommerce system that is both distinctive and flexible which aim is to elevate the performance of your online store. Sahara is a beautiful and distinct style that automatically attracts the shoppers and gives them a superb shopping experience. Access its premium features like customizable areas, mobile-friendly layout, and smooth connection with Shopify that give you the opportunity to build a stunning and tailored store that truly reflects your company.
Final Thoughts
The selection of the most suitable Shopify B2B themes is a tactical consideration rather than an aesthetic one. The appropriate theme facilitates complicated catalogs, different pricing, and slow sales while maintaining and even increasing the trust, clarity, and authority of the brand. No matter if your main focus is on growth (Expanse), conversion and credibility (Forge), balanced growth (Pursuit), or strong brand differentiation (Sahara), the most important thing is that your business model and storefront structure are perfectly aligned.
If you are going to build or migrate a B2B Shopify store and need a theme that supports growth, not just looks good, we can assist you in the evaluation, customization, and implementation of the right solution. Contact us to convert your Shopify B2B theme into a platform that drives revenue.
FAQs
What makes a Shopify theme suitable for B2B?
A B2B Shopify theme supports large catalogs, detailed product data, flexible layouts, and integrates well with wholesale pricing, custom accounts, and bulk ordering workflows.
Can standard Shopify themes work for B2B stores?
Yes, but only if they’re structurally flexible and compatible with B2B apps or Shopify B2B features; many consumer-first themes struggle with scale and complexity.
Which Shopify theme is best for large B2B catalogs?
Expanse is particularly strong for large inventories, complex product hierarchies, and content-heavy product pages.
Are these themes compatible with Shopify Plus B2B features?
Yes, all listed Shopify wholesale themes can work with Shopify Plus, provided they’re properly configured and extended where needed.
By the time eCommerce transforms into an AI-operated, no-channel limitations, completely tailored experience, the brands and agencies would have been through events focused on offering strategic insights and opportunities for significant business growth.
The list of eCommerce events in the USA backs this idea with the major trends of the year being AI push, selling via all channels, retail media, personalization, customer satisfaction, and international retail. These lectures will allow you to keep track of things regardless if you are a company founder, eCommerce executive or agency head.
Why Attend Conferences and Events This Year?
The conferences in the eCommerce industry are not only about the free tote bags (but Shoptalk has some very nice ones). They are about getting away from the never-ending Zoom discussions and going to the real world, where you can pick up good ideas from people who really know what you are going through.
No matter if you want a revolutionary way of doing things or just an easier way to look at your latest issue or simply someone who understands why your Slack channel is full of GIFs of dumpster fires, these conferences will provide. Moreover, who among us would like to miss the chance to spend money on a trip and come back looking like a visionary?
Thus, pick your favorites, purchase your ticket, and get ready to have a little bit of an awkward conversation over coffee. Your future self, and maybe even your KPI chart, will be grateful to you.
Full Repertoire by City & Date
A complete listing of all the top eCommerce and retail conferences for 2026, sorted by location and date, is displayed in this comprehensive table. The events range in America and even more so in the larger cities like New York, Los Angeles, Miami, and Boston, and it furthermore lists conferences that cater to management, brand leaders, and tech experts.
Besides all that, there’s a note about the intended audience for every event which means that eCommerce professionals can easily pick the event that suits their needs the best, whether it’s new retail, subscription services, omnichannel tactics, or sophisticated customer experience and IT solutions.
| City | Date | Event | Notes |
| New York, NY | May 20-21, 2026 | The Lead Innovation Summit 2026 | Fashion, beauty, retail innovation leaders; VC and emerging brand founders; commerce-tech executives |
| New York, NY | June 23-24, 2026 | CommerceNext Growth Show 2026 | Retail, DTC brand leaders, marketing & technology strategists |
| Seattle, WA | Jan 25-28, 2026 | Acumatica Summit 2026 | Technology and ERP/commerce integration leads, agencies |
| Miami, FL | Feb 4-5, 2026 | EEE Miami 2026, eCommerce Experience Evolution | Brand executives, eCommerce leaders, founders |
| Miami Beach, FL | June 1-3, 2026 | Glossy E-Commerce Summit 2026 | Beauty, fashion, wellness brands; retail-brand officers; omnichannel strategists |
| Palm Springs, CA | Feb 23-26, 2026 | eTail Palm Springs, eCommerce & Omnichannel Retail Conference | Brand executives, eCommerce leaders, founders |
| Las Vegas, NV | Mar 24-26, 2026 | Shoptalk, Retail’s Community of Changemakers | DTC brands, retail innovators, marketplace & growth teams |
| Las Vegas, NV | Apr 19-22, 2026 | Adobe Summit 2026, The Digital Experience Conference | Marketing leaders, CX architects, personalization teams, enterprise brands |
| Las Vegas, NV | Oct 26-29, 2026 | SuiteWorld 2026 by Oracle NetSuite | Brands using NetSuite, complex commerce and finance/operations teams |
| Los Angeles, CA | Apr 8-9, 2026 | ChargeX Event by Recharge | Subscription commerce teams, retention/renewal operators, partner agencies |
| West Hollywood, CA | Apr 23, 2026 | GROW LA 2026 | eCommerce operators, mid-market and growth brands, tech providers, agencies |
| Atlanta, GA | May 4-6, 2026 | Gladly Connect Live 2026, CX Event | CX leaders, eCommerce service/operations teams, customer-experience strategists |
| Kansas City, MO | May 13-15, 2026 | SubSummit 2026 | Subscription-model businesses, retention/renewal teams, recurring-revenue operators |
| Boston, MA | Aug 10-12, 2026 | eTail Boston 2026 | eCommerce strategists, marketing leads, omnichannel operations teams |
Participation in these occasions gives you a unique chance to not only keep yourself informed of the trends but also to connect with top people in the industry as well as to learn what would really help you to grow your eCommerce business. If you use this list, then you can think about your conference attendance for 2026 in a very clever way, making sure you are present at the events that match your company, market, and career goals.
How to Choose the Right eCommerce Conferences to Attend
All the mentioned things can be expected to some extent, but still, there are conferences that offer more value than others. In addition, the mere concept of the “best eCommerce conferences 2026 USA” can vary depending on various business factors. So, what is the way not to throw away your time and money? The answer is simply to align the eCommerce live event to your current needs.
- Understand your goals. Before you look at any conference lineup, get clear on what you’re trying to accomplish. A conference packed with sessions on scaling from $10M to $100M won’t help much if you’re still figuring out your first six figures.
- Check the audience. The attendee list matters as much as the speaker roster. Some conferences attract enterprise teams, while others draw small business owners and solopreneurs. Look at past attendee profiles to understand it.
- Evaluate the content. A good conference balances inspiration with practical takeaways you can actually implement. Check if there will be specific tactics and strategies, case studies, workshops, and networking – not just theory.
- Consider the logistics. The best conference in the world doesn’t help if you can’t justify the cost or time away. Evaluate the timing and total investment costs. It all should make sense for your budget. Also, keep in mind that some conferences offer virtual options.
- Look at the ecosystem. Check for side events, meetups, or unofficial gatherings happening around the conference. Sometimes the best value comes from those.
At last, rely on your instinct about the culture fit. There’s an atmosphere in every conference. If it’s kind of a serious event or a get-together you should, more than just being a passive observer, pick the place that seems correct and where you’ll participate.
Final Thoughts
It is essential to participate in the suitable eCommerce conferences 2026 USA in order to remain on top of things in a fast-changing landscape. The conferences of this kind do provide direct growth, customer experience, and revenue impact through insights, networks, and strategies that are all very useful.
When you take part in conferences that resonate with your aspirations and audience, the acquisition of knowledge will be very practical, very important contacts will be created, and the security of your business will be guaranteed for the future. Get an eCommerce consulting and utilize the full potential of 2026 to get actual eCommerce ventures results through the driving of the good ones.
FAQs
Why should I attend eCommerce conferences in 2026?
eCommerce conferences of 2026 in the USA provide actionable insights, networking opportunities, and strategies to help brands and agencies stay ahead in AI-driven, omnichannel, and personalized retail landscapes. They go beyond theory, offering practical takeaways and real-world inspiration.
Which conferences are most relevant for eCommerce leaders and brand founders?
Events like Shoptalk, The Lead Innovation Summit, eTail conferences, and Adobe Summit are geared toward executives, marketing and CX leaders, DTC brands, and growth-focused operators. Each event highlights innovation, strategy, and business development opportunities.
How do I choose the right conference to attend?
Align the event with your goals, target audience, and business stage. Check attendee profiles, evaluate the content for actionable insights, consider logistics, and explore side eCommerce events in the USA or networking opportunities to maximize ROI.
Are these events suitable for tech or agency teams?
Yes. Conferences like Acumatica Summit, ChargeX, and SuiteWorld cater to technology, ERP, subscription commerce, and partner agencies, providing strategic sessions and practical workshops.
Unfortunately, a majority of companies believe that it is better to have more visitors and do not care about maximizing the value of those who come to their online store.
The reality is that business growth is driven by conversions, not by the number of visitors. Knowing how to raise your conversion rate is what turns visitors into customers and directly increases your income.
This post will talk about the importance of conversion rate improving. Along with that, there will be practical ways for you to increase it by means of effective eCommerce conversion rate optimization. We are going to guide you through every step of the process, so you’ll be able to apply it and steadily grow your business regularly.
Why Conversion Optimization Matters in 2026
CRO continues to evolve from a set of simple UI tweaks into a structured, data-driven discipline. The goal remains the same – increasing the share of visitors who take meaningful actions – but the way companies approach CRO in 2026 is far more sophisticated. Modern optimization relies on behavior analytics, UX research, and first-party data to help businesses focus not just on conversions, but on qualified conversions that bring long-term value.
Industry reports throughout 2025 showed a clear pattern: brands that moved beyond surface-level experiments (like button colors or headline swaps) saw much stronger, more stable results. The companies that performed best were those combining several methods at once – continuous A/B testing, behavioral insights, personalization, trust-building elements, and multi-step customer journeys.
Across these studies, one theme kept repeating: reducing friction and creating a more “human” experience drives the biggest gains. When pages load fast, navigation feels intuitive, communication is transparent, and recommendations are relevant, users are simply more willing to trust the brand. And because these improvements are guided by first-party data, teams can measure their impact accurately and scale what works.
This shift explains why CRO is so important in 2026 – it’s no longer about isolated quick wins, but about building a long-term optimization system that continuously increases revenue and customer lifetime value.
Analyzing Customer Behavior and UX
A plethora of eCommerce conversion rate optimization methods are mainly based on different figures such as percentages, averages, and benchmarks. Even though the conversion of visitors into buyers is the main target of CRO, it will not help you much if you only depend on numbers. The more time you spend looking at the spreadsheets that are filled up with data points and actions, the more you will overlook the people who are behind them.
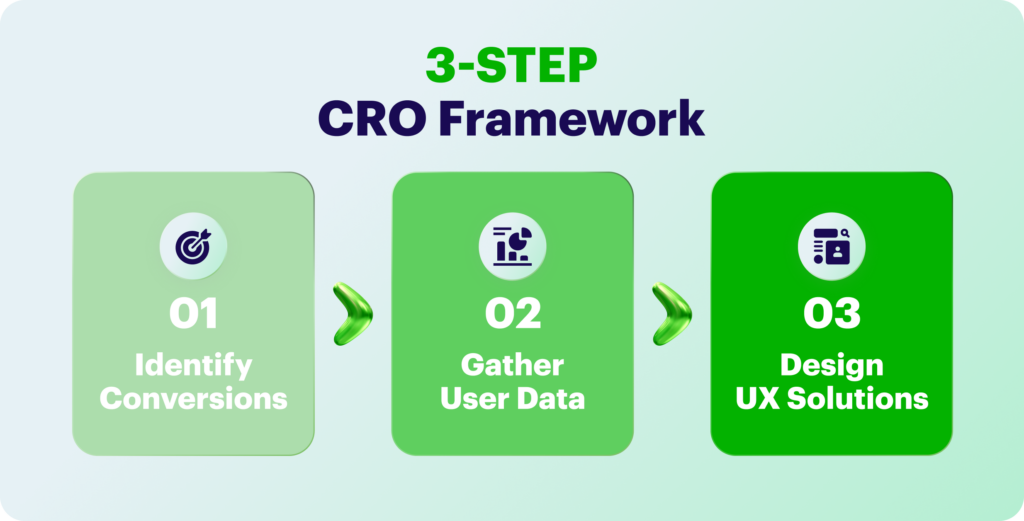
The people-centered strategy in the case of the holistic CRO eCommerce draws their attention and tries to find out what factors drive, what factors deter, and what factors convince them to buy. The very first thing that needs to be done is establishing a link between UX design and customer behavior.
Step 1: Identify Important Conversions
Conversions, or the specific actions you wish to see more users doing, differ from one business to another and are depending on your goals. If you are running an online store, a completed order could be considered a conversion.
When you have already specified the activity you want to focus on, you can enhance the rate at which visitors do it. To put it differently, ‘conversion rate’.
Step 2: Gather User Data
Once the significant drop-off points in the conversion funnel have been recognized, the next step is to start collecting a substantial amount of information about your users. This can be considered the most important stage in every user-centric CRO eCommerce method and you will find that not all the factors preventing conversions are measurable or evident.
When it comes to the final step, the conversion, focusing on that aspect is essential. Nevertheless, there is a lot going on before reaching that stage:
- some particular incentives attract users to your site
- some exclusive obstacles make them go away
- some unique appeals persuade people to take the action
On occasion, a problem is as simple as a lone bug hindering 80% of the users to carry out a required action. However, your site could be running perfectly, yet still, visitors do not convert. In this case, you will have to continue looking into the reason behind the data and concentrating on your users’ requirements, which is the essence of CRO.
Step 3: Design UX Around Customer Insights
Once the user data has been gathered, the next step will be to transform the identified drivers and barriers together with the tested hypotheses into UX optimization of great importance. User experience creations reflecting the up-to-date signals of demand, reduced friction, and smoothly conducted conversions are planned as the primary objective.
First and foremost, it is important to develop the user journey map. Display clearly each step from getting in touch to successfully converting and putting under each stage pain points, moments of friction, and delight. The user data you have collected can help you to point out places where users abandon, are stuck, or are not clear about the process.
After that, begin with the changes that will have the greatest impact on conversions. To illustrate, if surveys indicate that users abandon checkout due to shipping costs being unclear, do checkout optimization where the costs are to be displayed upfront in a very clear way. If statistics reveal that users frequently click on the wrong CTA, alter the button’s location, color, or text accordingly.
Always apply the core principles of usability when making UX decisions. A few fundamentals consistently help improve conversions:
- clarity – keep instructions straightforward and avoid unnecessary wording, so users immediately understand what to do.
- simplicity – remove steps, visual noise, or distractions that don’t contribute to the task.
- feedback – let users know what’s happening after they click, submit, or interact with an element, so they feel in control.
- consistency – use familiar patterns, similar layouts, and predictable behaviors across all pages to reduce cognitive load.
Wireframes or low-fidelity prototypes are suitable for testing new UX features in advance of their complete implementation. The intention is to make the design decisions based on the real user experience.
Top CRO Techniques That Work
CRO is more than numbers and analytics dashboards. The strongest results usually come from a mix of psychology, UX, and continuous testing. Here are a few practices that consistently move the needle:
- personalization helps shape content, offers, and messaging around what each user actually does on your site – their behavior, past interactions, and preferences; this creates a sense of relevance and usually lifts engagement and conversions
- trust elements reassure visitors that your brand is legitimate and safe to buy from; reviews, testimonials, security badges, certifications, and third-party mentions all reduce hesitation and make the next step feel easier
- fast loading pages keep people from dropping off; slow sites frustrate users and increase bounce rates, so optimizing images, using caching, and cleaning up code can have a direct impact on conversion rates
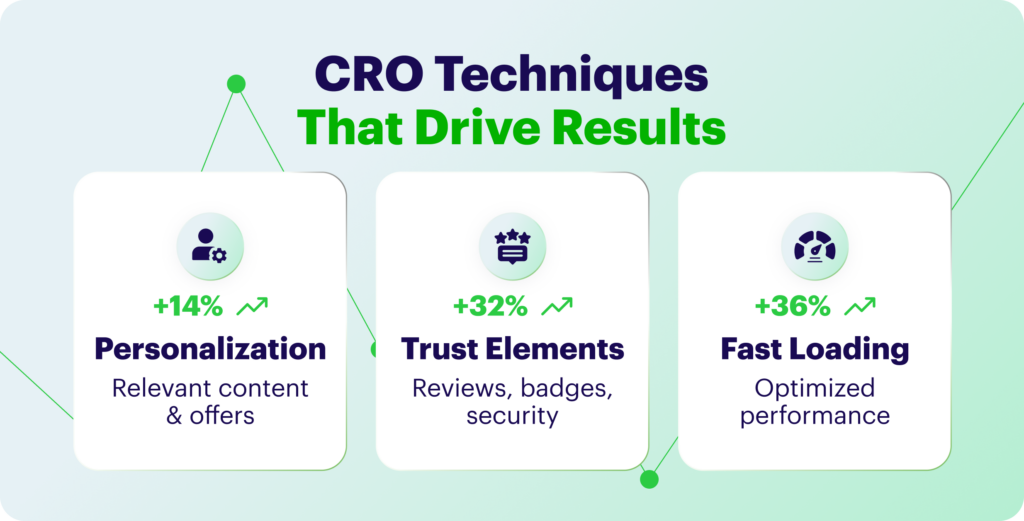
CRO isn’t something you set up once – it grows through testing, learning, and small, repeated improvements. Personalization, trust, and performance are the base, but the biggest gains come from analyzing how people behave on your site and refining the experience week after week.
Tools to Track and Improve Conversion Performance
To measure the efficacy of your CRO initiatives, you must use dependable techniques that provide both quantitative and qualitative data. Tracking user behavior and conversion metrics allows you to make more educated decisions about UX, content, and conversion funnel optimization.
1. Analytics Platforms
You can track traffic, page views, bounce rates, and conversions using tools such as Google Analytics, Adobe Analytics, and Matomo. They assist you in determining which sites work effectively, where users drop off, and how different traffic sources contribute to conversions.
2. Heatmaps and Session Recordings
Hotjar, Crazy Egg, and FullStory are platforms that visually demonstrate how users interact with your website. Heatmaps show which regions receive the most clicks or attention, whereas session recordings allow you to observe actual user journeys and identify friction points or confusing parts.
3. A/B and Multivariate Testing Tools
Tools such as Optimizely, VWO, and Google Optimize allow you to test numerous variations of pages, headlines, and CTAs to see which version generates the most conversions. Testing helps to validate hypotheses and avoids guessing in UX design.
4. Feedback and Survey Tools
Obtain direct user feedback using platforms such as Typeform, SurveyMonkey, or in-page widgets from Hotjar or Qualaroo. Understanding why consumers behave in specific ways allows you to identify hidden barriers and improve the overall experience.
5. Conversion Funnels and CRM Analytics
Using HubSpot, Salesforce, or other CRM-integrated technologies, you can track leads and conversions across the whole customer journey. Marketing touchpoints can be linked to boost eCommerce sales outcomes to uncover high-impact improvement opportunities.
You can develop experiences that organically direct visitors to conversion by reading your consumers, aligning UX with their behavior, testing hypotheses, and utilizing proven CRO approaches like customization, trust signals, and site speed. The key to success in 2026 is a data-driven, iterative approach that combines insights, action, and continual improvement.
Ready to convert more visitors into loyal customers? Stellar Soft commerce enables you to apply advanced CRO methods, optimize your eCommerce UX, boost eCommerce sales, and track performance with precision. Begin improving your website today. Book a demo or learn more about our solutions to increase conversions and drive long-term growth.

Real CRO Results: Examples from Stellar Soft Portfolio
Numbers and tools are useful on their own, but they become truly meaningful when tied to real projects. Below are a few snapshots from our CRO portfolio that show how analytics, heatmaps, testing, and UX changes translate into revenue and lead growth.
Fashion eCommerce – fixing product discovery on mobile
Using Google Analytics and Hotjar, we saw that mobile visitors were spending time on category pages but rarely opening product pages. Heatmaps showed that filters and size options were hidden too low on the page. After moving filters higher, simplifying the grid, and testing several mobile layouts, the store achieved:
- +26% increase in product detail page views
- +14% growth in add-to-cart rate on mobile
- lower bounce rate on key collection pages
Beauty subscription brand – checkout friction and trust signals
Session recordings and exit-intent surveys revealed that many users abandoned the checkout on the payment step because delivery time and return conditions were unclear. We redesigned the checkout to highlight shipping estimates, guarantees, and trust badges, then A/B-tested clearer CTAs and shorter forms. As a result:
- checkout completion rate grew by 18%
- overall subscription sign-ups increased by 12%
- support tickets about “where is my order?” dropped noticeably
B2B equipment supplier – long forms and weak lead quality
For a B2B client, CRM data showed that a large share of marketing leads never progressed to qualified opportunities. Analytics and funnel reports pointed to a complex quote form with many optional fields. After restructuring the form, splitting it into steps, and testing different field orders, the client saw:
- +21% increase in completed quote requests
- higher share of sales-qualified leads (up by 17%)
- shorter response times from the sales team thanks to cleaner data
Global lifestyle brand – pricing and offer experiments
Using VWO and first-party analytics, we ran a series of A/B tests on promotions, bundles and pricing presentation. Instead of offering site-wide discounts, we focused on value-based bundles and clearer savings messaging. Over several test cycles, this led to:
- +9–15% uplift in revenue per session on tested segments
- more stable margin compared to blanket “-20% for everyone” campaigns
- better understanding of which benefits resonate with different customer groups
These and other cases from our CRO portfolio show the same pattern: when you combine behavioral data, user feedback, experimentation and careful UX changes, conversion growth stops being guesswork and becomes a repeatable process.

The most vocal supporters of this commerce model cite a variety of reasons for establishing a headless architecture, including substantial increases in site performance and unprecedented agility to make changes on the fly. On the surface, going headless sounds like a no-brainer, right?
Headless commerce provides marketers with complete creative freedom while also allowing developers to create bespoke eCommerce experiences using their composable commerce tech stack. However, implementing a headless architecture is not as simple as it may appear. So you need to understand what it means to go headless. We’ll also walk you through the basics of headless architecture.
What Is Headless eCommerce?
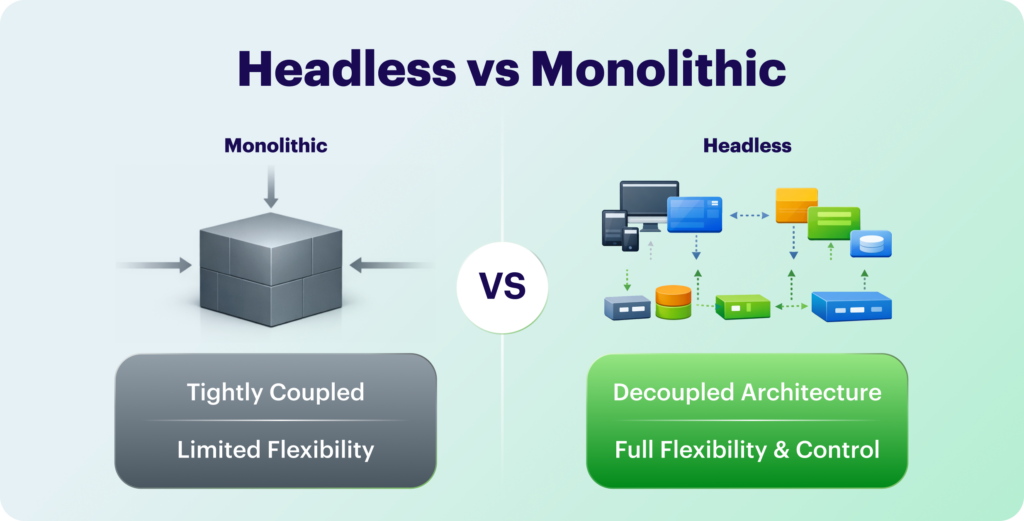
In general, headless eCommerce is an architecture that separates the customer-facing “head” from the “body” (back-end, or structural logic), allowing for complete freedom to create unique shopping experiences on any device (web, app, IoT) via APIs without being tied to a rigid platform, making it flexible, fast, and omnichannel-ready for changing customer demands.
A monolithic design is based on a single codebase, which means that any changes made to the front-end have an immediate impact on the back-end. This implies that connections with social media platforms or other third-party vendors may not be fully compatible with the rest of your eCommerce experience. In other circumstances, you may be unable to make the desired changes to the front-end of your monolithic system due to back-end restrictions.
Unlike a monolith, a headless commerce architecture allows you to modify front-end features like the user interface or design without affecting the back end. This decoupling can give you a much clearer path to designing custom eCommerce store experiences that are dynamic, performant, and scalable as your business expands.
Advantages of Headless Architecture in 2026

How much of the purchasing process should you manage yourself? That’s headless vs. theme-first. In 2026, eCommerce theme reliance is rarely a one-size-fits-all decision.
Developers are eager to go headless because it provides a high level of development control and allows them to combine tech stacks with their preferred best-of-breed commerce tools.
- You can design several front-end experiences for various customer touchpoints. Your online, mobile, voice, and point of sale (POS) front-ends may communicate with a single backend system via the API eCommerce layer, allowing companies to expand globally.
- On the backend, you can leverage fine-grained services to suit your brand’s complicated operational requirements. Because your technology stack is modular, you can easily integrate headless CMS, CRM, or DXP. There is also no vendor lock-in, allowing you to switch between different services as your needs evolve.
When does building a headless commerce architecture make sense? When your buyer experience resembles a custom internal application rather than a standard storefront, decoupling your front-end is the best course of action.
Headless for Magento and Shopify Stores
For many brands, the headless conversation starts with the platforms they already use most – Magento (Adobe Commerce) and Shopify / Shopify Plus. Both platforms support APIs and modern developer tooling, which makes them natural candidates for a gradual move toward headless.
On Magento, headless is often used to overcome limitations of heavy, legacy themes and long deployment cycles. A decoupled React or Vue storefront (for example, via Magento PWA Studio or a third-party PWA framework) can dramatically improve page speed, Core Web Vitals, and mobile UX without replacing the entire commerce engine. This approach is especially relevant for merchants with large catalogs, complex pricing rules, or multi-store setups.
On Shopify, brands usually consider headless when a standard Liquid theme can no longer support the level of customization they need. Using Hydrogen or another custom frontend, teams gain more control over layout, content, A/B testing, and performance, while Shopify remains the stable transactional backend for products, orders, and payments.
In both cases, headless does not mean “abandon Magento or Shopify.” Instead, it allows you to keep a proven commerce core while upgrading the customer experience layer. That’s why many mid-market and enterprise merchants view headless Magento or headless Shopify as a way to extend the life of their current platform, rather than a full replatform from scratch.
Custom Shopping Experience and Full Control
With a headless design, the decoupled user interface is completely customisable. Multiple, tailored front ends can be designed for various channels and audiences. You can create your storefront with whatever technologies, tools, and frameworks work best for you. This enables you to provide fully tailored purchasing experiences for various audiences.
Headless commerce can offer a personalized experience to each type of buyer. To satisfy buyer preferences, you can add custom functionalities as well as change content and the purchase experience.
Lessen Time to Market and Targeted Scalability
With the front end and back end segregated, developers may work on website features and enhancements individually before launching them. This enables businesses to integrate new features more quickly without having to worry about the impact on other portions of the website.
To boost performance, add more frameworks, codebases, and other front-end resources. For B2Bs that wish to provide totally separate front-ends for different customer bases, a headless solution allows them to manage everything from a single unified back-end, easing operations and workflows. Resources may be scaled independently, providing for a more agile and flexible reaction to expansion and rising client demand.
Integratable with Preferred Tools and Services
When your store uses a headless architecture, you have the ability to interface with your existing systems via APIs. ERP, CRM, IMS, WMS, and PIM are some examples of such systems.
Integratable with Preferred Tools and Services
Headless architecture makes it easy for your store to connect with existing business systems through APIs. This includes ERP, CRM, IMS, WMS, PIM, and other tools that support your operations.
When these systems work together, they simplify workflows and keep your data consistent across every channel.
Here’s how these integrations typically help:
ERP integration
Connecting your store with an ERP keeps product information up to date in real time and ensures accurate stock levels across every storefront. It also streamlines order routing and fulfillment, adapting to customer preferences and giving shoppers clear information about their orders.
CRM integration
A CRM gathers customer data from all touchpoints, helping your team provide more personalized service. It becomes easier to tailor product suggestions, run targeted marketing campaigns, and give support teams the details they need to assist customers quickly.
PIM integration
A PIM system keeps product content consistent across all your sales channels. It helps maintain accurate descriptions, technical details, and attributes, which is especially important for large catalogs. With cleaner data, you can also deliver more relevant product recommendations.
Aside from those three major integrations, a headless strategy enables businesses to connect with advanced third-party technology such as chatbots, voice assistants, and AI tools. It adds up to a modern customer experience, regardless of how many different types of clients you have.
Real-World Use Cases and Brands Using Headless

Both Stellar commerce scenarios demonstrate the revolutionary power of headless and microservices architectures, whether they improve a consumer-facing marketplace or modernize industrial B2B procedures. Key themes include divorcing frontends from legacy backends, incorporating AI for customisation, and developing future-proof systems.
The technical approach used during the project included the following methods:
Headless backend separation and API layer
We decoupled the storefront from the legacy monolithic platform and introduced a dedicated API layer based on REST/GraphQL.
This allowed product catalogs, pricing, account data, and checkout flows to be delivered independently to any frontend (web, mobile, or native apps).
PWA storefront built with React / Vue.js
A new Progressive Web App storefront was developed using React (or Vue Storefront – в зависимости от твоего реального стека).
Pages are rendered dynamically, with only essential data fetched on demand. This improved initial load times, helped achieve a mobile-first UX, and reduced server load during peak hours.
Image optimization and performance tuning
We implemented lazy loading, WebP image formats, CDN delivery, and dynamic compression – critical for a cosmetics marketplace with large visual assets.
This improved Core Web Vitals and increased mobile conversions.
Search, filtering, and personalization enhancements
An improved search and filtering engine (ElasticSearch / Algolia / Meilisearch – выбери что вам подходит) was added to handle:
- typo-tolerance
- fast autocomplete
- filtering by shades, brand, skin type
- personalized ranking based on browsing behavior
This made product discovery faster and more accurate, especially on mobile.
Scalable architecture for high traffic
The backend and storefront were deployed using cloud-native hosting (AWS / GCP / Vercel), enabling automatic scaling during promotional periods or new product drops.
This solved the previous performance bottleneck caused by traffic surges.
Integration with mobile apps
Instead of maintaining two separate native applications, we implemented a unified API that feeds the PWA storefront and both Android/iOS apps.
This reduced development overhead and improved consistency between platforms.
Mobile conversion rates rose by 48% thanks to PWA performance and AR features. Real-time, AI-powered product suggestions improved CX at scale. Integration with Amazon Payment Services and logistical systems made checkout and fulfillment easier.
The role of headless PWA architecture in connecting legacy systems with modern, mobile-first user experiences while allowing for ongoing innovation and customisation.
Microservices-Based Digital Transformation in Industrial B2B (Rewritten Case Study)
A German industrial manufacturer of gas-analysis equipment needed a full eCommerce overhaul. Their legacy platform relied on manual order handling, disconnected data sources, and a monolithic store that could no longer support modern B2B requirements such as multi-warehouse inventory, account-level pricing, and automated customer operations.
The goal was clear: build a scalable, API-driven B2B storefront that supports automation, real-time data flow, and global expansion.
What We Delivered:
Digital Transformation Roadmap
We began by mapping the existing digital ecosystem: data flows, customer journeys, order lifecycle, and operational bottlenecks. Based on this audit, we created a strategic roadmap and a Work Breakdown Structure (WBS) outlining recommended technologies, architecture changes, and implementation phases.
Migration to a Composable Commerce Architecture
We rebuilt the store on commercetools (MACH architecture) – a microservices-based, cloud-native, API-first commerce platform.
This allowed the client to:
- decouple frontend and backend systems
- scale individual services without affecting the entire system
- reduce deployment risks
- quickly introduce new digital features
SAP ERP Integration
We established real-time two-way synchronization between the new storefront and the client’s SAP ERP.
This integration enabled:
- precise multi-warehouse inventory
- automated order creation and routing
- synchronized pricing and customer-specific terms
- consistent product data across all sales channels
UI/UX Overhaul
We redesigned the navigation, catalog structure, and account dashboards based on behaviour analytics from real B2B buyers.
The new UX improved:
- product discovery speed
- time-to-order
- repeat purchase rates
- error rates in order placement (dropped by 22%)
AI-Driven Search & Product Discovery
We implemented Algolia to support:
- tolerance for misspellings (critical for technical SKUs)
- dynamic ranking based on user behaviour
- personalized search suggestions and frequently purchased items
- faster filtering for complex product attributes
This significantly reduced search friction for B2B procurement teams.
Business Impact
After the rollout, the company moved from outdated manual workflows to a modern, automated digital commerce system. Measurable results included:
- 25% reduction in total cost of ownership due to microservices and cloud infrastructure
- 30% increase in B2B conversion rate thanks to UX improvements and enhanced search
- real-time visibility into orders, pricing, and stock across all business units
- faster onboarding of new international markets due to modular architecture
- significant drop in operational errors thanks to automated data synchronization
This transformation equipped the manufacturer with a future-ready, flexible B2B commerce platform capable of supporting industrial-grade processes, multi-market expansion, API integrations, and advanced customer workflows.
The new microservices architecture gives their teams the ability to innovate quickly, while ERP integration ensures stable day-to-day operations. Together, this creates a long-term technical foundation for scaling their digital business globally.
Is Headless eCommerce Right for Your Business?
If your store runs smoothly on a traditional architecture and you’re not struggling with performance or flexibility, switching to headless may not bring enough value to justify the investment. Everything depends on your long-term goals and how fast you want to innovate.
Many companies start considering headless after facing a similar set of challenges. For example, their current platform may be stable, but every new feature becomes a slow and complicated process. Competitors might be moving faster simply because they can update the frontend and backend independently.
Some businesses start noticing that customers expect quicker, more polished shopping experiences across all devices, yet the existing system cannot deliver that speed or level of control.
Others hit personalization limits – templates, themes, and built-in settings stop allowing further growth.
And in more advanced cases, brands want to experiment with new retail formats such as smart mirrors, wearables, in-store devices, or automated vending commerce, but their current platform cannot support these ideas.
Before moving to a headless setup, it’s important to evaluate the costs and the time commitment. Enterprise-level projects vary significantly, ranging from hundreds of thousands to several million dollars depending on integrations, customization, and architecture.
If the challenges above resonate with your situation, it may be a good moment to consider a headless approach. Stellar Soft can audit your existing system, propose an optimal architecture, and build a practical roadmap focused on performance, personalization, and measurable ROI.

Discover the trends that will alter how we discover, purchase, and engage with things in the coming year. Continue reading to understand how to positively future-proof your business.
Market Shifts Define Trend Baseline for The Following Year
The global business-to-business (B2B) eCommerce market is predicted to develop at a 14.5% CAGR until 2026. Some eCommerce trends to keep an eye on in the coming year include virtual and augmented reality, mobile shopping, more payment options, voice search, AI eCommerce, data forensics, and ethical branding. Begin implementing these eCommerce trends by making your brand sustainable and ecologically conscious.
The United States continues to have one of the largest global eCommerce innovation markets, with online sales expected to reach $1,036 billion by 2024. The Census Bureau reported $304.2 billion in seasonally adjusted sales in Q2 2025, up 1.4% from the previous quarter and 5.3% from Q2 2024. Unadjusted, these sales totaled $292.9 billion, representing 15.5-16.3% of overall omnichannel retail sales.
However, the main market movement that defines such a trend baseline for the following 2026 year happened significantly earlier. During the COVID-19 pandemic, many brick-and-mortar businesses struggled to maintain constant sales, while others focused on internet sales. The expected growth of global eCommerce markets can be used by online brands to identify this trend.

Mobile Shopping Continues to Dominate the eCommerce Landscape
Mobile commerce is no longer an optional channel – it is steadily becoming the primary way customers browse, compare, and purchase products online. Instead of relying on desktops, users increasingly make buying decisions directly from their smartphones and tablets. This shift is not temporary: according to Statista, global mobile commerce revenue has shown consistent year-over-year growth, and mobile now accounts for a substantial and expanding share of total online retail sales.
The trend is driven by several factors: faster mobile networks, seamless digital wallets, improved UX patterns for small screens, and the growing influence of social commerce. Consumers expect instant access, frictionless navigation, and checkout processes optimized for handheld devices.
For eCommerce businesses, staying competitive means prioritizing mobile-first optimization across every part of the customer journey – from page speed and responsive layouts to product discovery, search experience, and one-click payments. Brands that adapt quickly to mobile-centered user behavior gain higher conversion rates, stronger engagement, and better long-term retention, while those relying on outdated desktop-oriented experiences risk losing visibility and revenue.
How Magento, Shopify, and Modern Platforms Align With 2026 eCommerce Trends

As new technologies continue shaping the digital commerce landscape, choosing the right eCommerce platform becomes a strategic decision. Magento, Shopify, and headless architectures each respond to 2026 trends in different – yet highly effective – ways.
Magento / Adobe Commerce: Built for Enterprise Agility
Magento (Adobe Commerce) remains the leading choice for mid-market and enterprise brands that require:
- deep customization and full control over code
- advanced B2B capabilities
- multi-store and international expansion
- large catalogs and complex pricing rules
- flexible integrations with ERP, CRM, and custom systems
Magento’s modular architecture makes it ideal for companies prioritizing:
- AI-driven personalization at scale
- custom checkout and payment flows
- PWA or headless storefronts
- long-term ownership of infrastructure and data
In 2026, businesses with complex digital ecosystems increasingly rely on Magento to support rich omnichannel experiences and fast adaptation to emerging AI tools.
Shopify & Shopify Plus: Optimized for Speed and Rapid Growth
Shopify continues to dominate among D2C, retail, and lifestyle brands that prioritize:
- fast go-to-market
- mobile-first storefronts
- streamlined app integrations
- built-in payment options (Shopify Payments, BNPL, wallets)
- simple and scalable management without technical overhead
Shopify’s strengths align perfectly with 2026 trends:
- the rise of mobile shopping
- growth of social commerce
- adoption of digital wallets and one-click checkout
- AI-powered tools built directly into the admin
Shopify Plus also unlocks enterprise features, allowing high-volume merchants to scale globally with minimal maintenance costs.
Headless Commerce: The Future of High-Performance Experiences
Headless solutions (Shopify Hydrogen, Magento headless with React/Vue, custom JAMStack builds) are rapidly gaining popularity in 2026 due to their ability to deliver:
- ultra-fast mobile and PWA experiences
- fully custom UX and design freedom
- seamless integration with AI, AR/VR, and personalization engines
- API-driven scalability across multiple front-end channels
Brands adopting headless commerce can adapt to new trends significantly faster without rebuilding their eCommerce engine.
Which Platform Fits 2026 Trends Best?
The answer depends on your business model:
| Business Need | Best Platform |
| Fast growth & mobile-first UX | Shopify / Shopify Plus |
| Complex enterprise operations | Magento / Adobe Commerce |
| Maximum speed & custom experience | Headless Commerce |
| Deep personalization & AI integration | Magento / Headless |
| Fast launch + low technical overhead | Shopify |
Platform Choice Is Part of Your Trend Strategy
Every 2026 trend – AI, mobile commerce, flexible payments, sustainability, AR/VR – is influenced by the technical capabilities of your eCommerce platform.
Choosing Magento, Shopify, or a headless setup determines how effectively you can implement these innovations and stay ahead of competitors.
Consumers Value the Flexibility of Payment Solutions
Customers hoping for convenience and simplicity may be thrown off by limited payment options and lengthy processes. eCommerce payment methods are developing, and buyers want multichannel shopping alternatives. Many businesses also provide flexible payment options such as “buy now, pay later,” mobile wallets, and the ability to pay using cryptocurrencies.
Increase in Use of Voice Search for Online Shopping
Recent surveys indicate that voice shopping search is becoming a significant aspect of the online purchasing experience. According to a 2025 survey by Capital One Shopping, nearly half of US consumers use speech-search to shop and roughly one-third have made purchases by voice. It is especially frequent with smart speakers like Google Home and Alexa, which enable users to purchase groceries and meals hands-free.
How AI and Automation Are Transforming eCommerce
According to eCommerce trends 2026, conversational AI will be much more than merely a supplement. It has already progressed beyond the initial stage. Conversational AI innovation is now an assistant that increases sales and brand loyalty through customisation and unique experiences. Personalization is extremely significant, particularly in mobile commerce, where it serves as a market differentiation.

Rather than providing product recommendations, information, or messages based on large user categories, eCommerce innovation businesses may tailor each shopper’s experience to a higher degree.
What Does This Look Like in Practice?
Here are some real examples of how data-driven personalization works in modern eCommerce:
Dynamic product page content
Smart algorithms adjust product page sections based on who the user is – their preferences, past behavior, or even how they interact with the landing page.
AI-enhanced search and product discovery
Instead of showing the same results to everyone, AI re-ranks items using a customer’s browsing history and intent, making search results far more relevant.
Personalized product recommendations
Recommendations are no longer random. They are generated from purchase history, viewed items, demographic data, and real-time behavior – showing shoppers exactly what they are most likely to buy.
Adaptive pricing and tailored offers
Some systems personalize discounts or pricing based on loyalty, sensitivity to price, or current market conditions, increasing the chances of conversion.
Smarter messaging across email, SMS, and Ads
AI analyzes engagement patterns to send messages at the perfect time and with the most relevant content, depending on each customer’s preferences and lifecycle stage.
Why is it important, you could ask? Today’s consumers expect personalization throughout the purchasing experience, and AI and social commerce helps to deliver on that expectation. Personalizing shopping experiences improves engagement, conversions, and income for your organization.
McKinsey and Attentive’s reports demonstrate this. According to the first source, 71% of consumers want organizations to provide tailored experiences, and 76% are upset when they don’t. According to the second source, 96% are likely to buy when messages are tailored, while 77% are persuaded by appropriate product recommendations.
Furthermore, Gartner estimates that by 2026, firms that effectively use AI eCommerce to tailor client buying experiences will be 25% more profitable than their competitors.
Significance of eCommerce Virtual and Augmented Reality
Augmented reality (AR) and virtual reality (VR) are increasingly used in eCommerce experiences. Previously only employed by Fortune 500 companies and enterprises, more firms are now utilizing these technologies to fully immerse clients in the purchasing process. It involves presenting customers with 360-degree views of products, viewing furnishings in virtual showrooms, and allowing them to digitally try on clothing.
How AR and VR Typically Work in Real Shopping Experiences
In real eCommerce scenarios, augmented and virtual reality show up in several practical ways that help customers understand products better and feel more confident before buying.
- Many stores now let shoppers “try on” items virtually – whether it’s makeup, glasses, or accessories – by placing them directly on the user’s face or body through the phone camera. It helps people see how something actually looks before committing to a purchase.
- For home and interior products, customers can place furniture or décor right inside their room using their smartphone. This helps confirm scale, style, and how the item fits into a real environment.
- Some brands recreate a full showroom experience online. Instead of browsing traditional product pages, visitors can move around an immersive digital space and explore collections as if they were in a physical store.
- Advanced sizing tools are becoming more common as well. By analyzing body measurements through a camera, these tools help determine the right size for clothing, shoes, eyewear, or other fitted items – reducing returns and uncertainty.
- And when products come in multiple configurations, AR previews let customers switch colors, materials, or finishes and instantly see how the final item will look once customized.
Agencies who help businesses flourish in this area do more than just install an AR viewer.
They include augmented reality into the entire buying process (from discovery to purchase) and tailor the brand’s ecosystem, such as a mobile app, website, or store, to accommodate these immersive features.
Why Sustainability and Ethics Matter for Modern Brands
Shoppers increasingly pay attention to the environmental and social impact behind the products they buy. They look for signs that a company treats workers fairly, uses responsible materials, and reduces unnecessary waste. This shift directly influences how much people trust a brand and how likely they are to return.
Across different studies, several trends appear again and again:
- many consumers say their confidence in a brand grows when it openly shares sustainability information, such as sourcing practices or packaging impact
- a large portion of shoppers choose products from companies with proven environmental credentials, even when these items are more expensive
- research based on supermarket sales shows that products made with higher animal-welfare standards often sell at a premium, which means ethical practices can translate into higher perceived value

When customers understand and agree with a brand’s values, they form a stronger emotional connection. Companies that support fair work conditions, transparent supply chains, and mindful production methods tend to build more loyal audiences and outperform competitors in long-term brand trust.
Adapting to the Future of eCommerce
Predicting the future of eCommerce may always need some educated guessing, but one thing is certain: every trend is based on one thing above all else: product data.

You don’t have to completely revamp your eCommerce firm to prepare for the future. Most of your rivals continue by focusing on three core infrastructural levels.
- Stabilize the foundation. Product, pricing, order, and customer data are all shared.
- Modernize the commercial core. An eCommerce platform that can support numerous business models, customize features, and integrate with AI without requiring frequent rewrite.
- Tune the levers. Smarter routing, improved store operations, and more flexible fulfillment.
Your competitors are already adapting to these changes. Those with greater infrastructure. They are experimenting with novel fulfillment models that do not require engineering rewrites. They are activating first-party data across channels, while others are still attempting to integrate their systems.
Gain an advantage by using Stellar Soft commerce to future-proof your store. From AI personalization to mobile optimization and sustainable eCommerce solutions, we help firms stay ahead of the trends in 2026. Begin the digital revolution of your store immediately. You can book a free meeting with our technical experts to discuss how your eCommerce can expand in the future.
The retail eCommerce sector is constantly growing and expanding its global reach, thus it is the most intense competition among the eCommerce retailers for consumer attention. One way to stay in tune with the changing consumer preferences and trends in the industry is moving your online store to a more secure platform.
We are going to guide you through the whole eCommerce replatforming checklist in this post, which includes all stages, security measures, and issues to be considered when changing from one platform to another.
What is eCommerce Replatforming?
eCommerce migration SEO is an easy process. The same setup is kept but it is moved to another host or platform. This could mean shifting from Shopify to WooCommerce or from shared hosting to managed cloud. Replatforming means building anew on a different base. You are changing processes, integrations, and shop architecture to make your site more scalable and SEO friendly.
During platform migration, everything that is essential to your business has to be moved carefully. Products, customers, orders, reviews, SEO data, and design settings must all be placed exactly where they are supposed to be. Even one error can cause your checkout to fail or make search engines confused.
The majority of the store owners’ reasons for moving are similar. They want their systems to perform better, to be less prone to breakdowns, and to have more space for growth. Some change their business location to lower the cost of maintenance or to allow the use of modern integrations. Finally, migration is a business upgrade rather than a technical task.
Associated SEO Risks
In theory, no move seems successful until it starts reflecting in lower revenues. Customers’ visits are the same, but the number of sales drops. Usually, this means that something didn’t work well during the transition from the old site to the new one.
The issues that caused the poor performance are rarely serious ones. It is the small and unnoticed factors that create big problems, such as not functioning redirects, unavailable information about the products, or difficulties in the checkout process that become apparent only when real customers start buying. We will elaborate on the most common reasons.
| Issue | What happens | Impact | Prevention tip |
| Poor Planning and Rushed Timelines | Skipped testing, underestimated data, going live at peak hours | Errors accumulate, costly emergency fixes | Create a detailed migration plan and test first |
| Broken URLs and Missing Redirects | Old links stop working after platform change | 404 errors, lost SEO ranking, reduced revenue | Maintain a redirect spreadsheet for all URLs |
| Incomplete or Corrupted Data | Missing images, duplicate SKUs, incomplete orders | Frustrated teams and customers, operational delays | Run a test migration to catch issues early |
| Checkout and Payment Failures | Broken gateways, tax/shipping errors | Lost sales, higher cart abandonment | Test all payment and shipping options before launch |
| SEO Oversights | Missing metadata, canonical tags, structured data | Drop in search rankings and organic traffic | Transfer SEO settings and sitemap carefully |
| Downtime During Launch | Old store taken offline too soon | Customers see blank pages, lost sales | Schedule launch with DNS propagation and contingency plan |
Having the previous store running until the new one is ready removes these gaps. Being able to spot these problems soon, you can plan a move that doesn’t stop sales.
Next time you want to move, first you need to find out if you need a complete replatform or just a standard platform migration.
How to Migrate a Store Without Sacrificing SEO

The process of moving successfully starts with careful planning, rigorous testing, and perfect execution. At each phase, the measures taken to ensure backups, testing, and everything that goes with it, protect your traffic and profit. Here is your eCommerce replatforming checklist:
- Prepare your store by backing up data, auditing performance, and creating a test environment.
- Move gradually with a platform migration tool or managed service, keeping your old store operational until everything is in order.
- Verify and monitor after launch to ensure that clients can continue to browse, pay, and order without issues.
Even though these steps look easy, dropping just a single one will cost you sales. The parts that are coming next explain each factor in detail going from planning through testing and post-launch optimization, thereby making your shop run without hitches and earning every moment.
Pre-Migration
A smooth transition is an aspect that can be tackled before doing the actual platform migration on the first file. The present planning will decide whether your shop gets a great start or has to struggle for weeks rectifying slight problems.
That phase lays the foundation for an effortless opening. Be prepared now so that your newly created online platform runs perfectly right from the beginning.
Step 1. Back Up Everything
Make a complete backup before alterations of any kind. This includes items, customers, orders, themes, and databases.
In case you are facing an issue, the previous version can be restored in no time. That backup will act as your safety net.
Step 2. Audit Your Current Store
Prior to migrating, an assessment of the current site is recommended to find out what is good and what is bad. The new site can very often be slowed down, made unresponsive, and overloaded with heavy plugins due to these problems.
Perform a rapid testing of the performance using PageSpeed Insights or GTmetrix as the tools of choice. Thereafter, resort to either Ahrefs or Screaming Frog for an in-depth scanning of your store, and thus, identify what metadata is missing and what redirects need to be addressed.
Step 3. Clean Your Data
Platform migration can be very difficult due to the presence of cluttered data. Take a look at the product catalogs, eliminate duplicates, and rectify any discrepancies in SKU or inventory.
Validation of the customers and orders is also necessary. To ensure that the imports are clean and quick, it is better to get rid of inactive accounts or test users.
Step 4. List All Integrations
Every retail outlet depends upon various connectors, including CRMs, payment gateways, email tools, and analytics. Keep track of the ones you will continue to use and the ones that need new connections.
Certain ones might need refreshed API keys or new plugins for the fresh platform. Preparing this in advance saves time lost due to unavailability later on.
Step 5. Create a Staging Environment
Never, under any circumstances, test migrations on your live website. A safe method for testing everything is to use a staging copy. You can import the products, check the checkout process and redesign the layout all before the official launch.
Step 6. Schedule the Migration
Timing plays a major role in this matter. For the purpose of mitigating risk, it’s advisable to pick hours with low traffic, which generally correspond to late-night or midweek hours. Consult your data to find the hour with the least activity and make the transition then.
Give a heads up to your team about the move so that no product or page editing takes place during the migration.
Step 7. Communicate Early
In case you have constant buyers or wholesale customers, inform them beforehand. If they recognize little changes in the layout, sending a simple update email strengthens trust and prevents doubts.
Clear communication keeps the customer’s trust during the transfer. When the data has been secure, clean, and tested, you are ready for data transfer.
During Migration
After completing all the preparations, it is now the moment to take the actual step.
This part of the procedure decides the extent of smoothness with which the new store will go live. Act slowly, check everything, and maintain the functionality of your old site until you are sure that the new one is perfect in every way.
Step 1. Pause New Orders and Content
Before starting, make sure to put a hold on your live store updates. There will be no new products, no changes in prices, and no customer orders through the transition.
Whatever changes you make now will not be carried over to the new platform till you do a manual sync of them later.
Step 2. Choose How You’ll Migrate
Manual migration, automated migration and semi-automated migration are the three basic methods for your eCommerce shop movement. Each one is suitable for different situations and levels of experience.
Usually, developers opt for manual migration when they want to have full control. The process involves exporting your database, using FTP to upload the files, and then manually importing the data. It may take longer, however it also gives the opportunity for more customisation.
Step 3. Test in Staging First
Before shifting to your live store, carry out the migration on your test website first. Check the display of products, pictures, and customer data. Go through categories, apply filters, and do some dummy purchasing. Getting errors caught early saves chaos later.
Step 4. Validate Your Data
Once the import is complete, make sure that all the items have been successfully delivered. Check the product quantities, customer lists, and order histories across the various platforms. In case anything is lacking, either reimport the portion or retrieve it from a backup.
Step 5. Test Checkout and Payments
The checkout procedure of yours is the stage where real money transactions actually happen, therefore it is recommended to carry out tests like a customer would.
Put items in your cart, conduct trial payments, and verify the purchase emails. If your sales are worldwide, have a try with different currencies and shipping areas. One small error can lead to the loss of hundreds of sales.
Step 6. Keep the Old Site Active
Don’t immediately change your DNS settings. During the test period, keep your previous store working so that customers can still place their orders in case the launch of the new site gets delayed.
Only when you are completely sure that everything is working well, can you then move the traffic to the new site without any risks. After you have confirmed your data and your new site has gone through all the necessary testing and passed, you are in a position to do the transfer. Prior to the launch, it is essential that you fortify your SEO base.
Post-Migration Testing & QA
When your new store goes live, the main focus becomes stability and visibility. It is best to test the website first like a genuine customer: go through the categories, visit the product pages, look at the images and variants, and see if there is any issue with layout. Simulate different scenarios during checkout by making payments with methods to different regions, and ensure that the confirmation emails and third-party gateways are working correctly.
All 301 redirects should be set up and verified; the next step is to crawl the site to discover missing pages, broken metadata, or SEO inconsistencies before the rankings drop. Page speed of your new store should be compared with that of the old one and slow pages optimized, as conversion rates are directly affected by performance.
Check the analytics for any drop in traffic or sales, reconnect all the integrations and automations that were put on hold, and take the final step of a full backup. This discipline is what transforms a technical launch into a stable, revenue-generating store.
Conclusion
A successful platform migration secures your traffic, data, and sales while also making your store ready for quicker growth. The gap between a hassle-free start and missed income is made up of planning, testing, and SEO discipline.
In case you are migrating to Shopify or Shopify Plus, Stellar Soft guarantees a proper migration with no traffic loss and no sales stoppage. Reach out to Stellar Soft to arrange your eCommerce migration the right way.
FAQs
What is eCommerce replatforming?
eCommerce replatforming is the process of moving your store to a new platform while redesigning architecture, integrations, and workflows to improve scalability and performance.
Will migration hurt my SEO?
SEO can drop temporarily if redirects, metadata, or site structure are mishandled, but proper planning prevents long-term losses.
How long does an eCommerce migration take?
eCommerce migration SEO takes 2-8 weeks, depending on store size, data complexity, and custom integrations.
Should I keep my old store live during migration?
Yes, keeping the old store live until testing is complete prevents downtime and lost sales.
What is the biggest risk during migration?
Checkout and payment errors are the biggest risk because even small issues can immediately stop revenue.
When should I consider Shopify Plus?
Shopify Plus is best for high-volume or B2B merchants who need advanced customization, automation, and enterprise support.
According to predictions, by 2026, AI chatbots for eCommerce will be no less than essential, stepping over foundational support roles and taking a proactive part in enhancing every single aspect of the customer journey. It is essential to comprehend the main areas of chatbot application that will be preferred by eCommerce companies as they are determinative for increasing sales, tailoring experiences, and reducing customer support dramatically.
Why eCommerce Needs AI Chatbots in 2026
The adoption of conversational interfaces is a sign that the consumers have changed their way of communicating with technology fundamentally. Messaging apps like WhatsApp and Instagram DMs have become people’s main digital communication channels. Companies that do not communicate via these channels are putting themselves in the position of being ignored by the market.
The companies will treat every chat interaction as a source of data. This gives them the power to shift the approach from marketing to extremely personalized and customer-centric experiences. Picture a chatbot that remembers the size of a customer, his/her past purchases, and even his/her preferred style, and then shows the customer some recommendations that seem less like a sales pitch and more like a personal stylist’s selection.
Product Discovery and Recommendation
In the year 2026, AI chatbots for eCommerce will be very well trained in assisting customers with large product ranges and will act as very knowledgeable salespeople who are always available. This is one of the main uses of chatbots which will be the major eCommerce companies to use this and increase the number of sales.
The chatbot does not wait for a customer to ask but instead, it starts interacting depending on the customers’ browsing activities. The chatbot suggests products and offers high-quality images and hyperlinks thereby making the customer’s selection more interactive.
This way, it reduces the eruption of customer indecision, increases the average order value (AOV), and most of all, it remarkably enhances the chances of sale since it matches the buyers with the right products much quicker than before.
Personalized Shopping Assistants (Rewritten, Natural Version)
By 2026, AI shopping assistants are expected to evolve into highly adaptive tools that recognize each shopper’s preferences, habits, and past behavior – not just recommend random items.
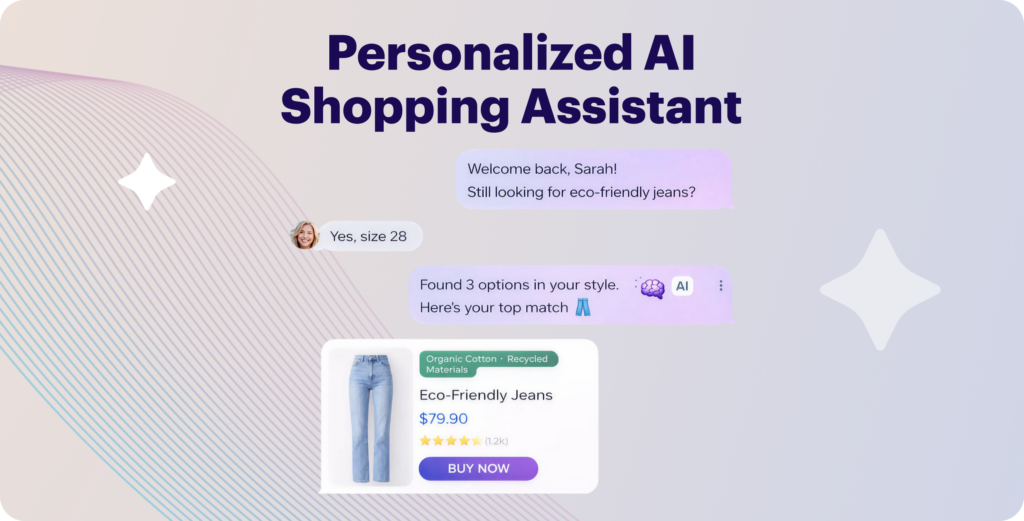
Here’s what this looks like in practice:
- when a returning customer signs in, the assistant greets them by name and brings up relevant details from past browsing or purchases. Instead of generic prompts, it might say something like “welcome back, Sarah – still looking for eco-friendly jeans, or maybe a matching top this time?” The assistant can answer product questions, compare items, and even check stock availability for specific sizes or colors
- when the interaction feels personal and relevant, shoppers tend to stay longer, enjoy the experience more, and come back again. This strengthens loyalty and increases the likelihood of repeat purchases
According to a FICO customer-experience survey, 88% of respondents say that the experience a brand provides matters just as much – or more – than the product itself.
Automated Order Management and WISMO Queries
The “Where Is My Order?” (WISMO) inquiries still constitute a significant burden on support staff. However, the chatbots’ role in this scenario will be nearly wholly automated by 2026, so the use case will be of utmost importance for eCommerce to get the most out of chatbots. All it takes is for customers to either type or say their order number or email address and the chatbot will with no delay connect to your shipping and order management systems.
This, in turn, allows the support agents to concentrate on more complex queries, brings the AHT down to a very low level, and provides the customers with instant reward which in turn leads to increased customer satisfaction.
Post-Purchase Engagement and Feedback Collection
The customer’s journey certainly does not finish at the payment. The whole process would not be able to function properly without chatbots that will still be very much alive during loyalty building and providing important business insights.
At times, a chatbot could be in touch with the customer a couple of days after the product was received just to get opinions about the product, give tips on usage, or even suggest similar items. The chatbot might also take care of returns and minor issues at the same time collecting information on customer satisfaction.
What you get is not only a better customer experience overall but also a stress-free situation, important data for the product, and through consistent engagement more customers returning to your business.
Benefits of AI Chatbots for Online Retail
The employment of a chatbot in digital customer communication in retail is a quick return on investment. Previously, suitable solutions had to be designed individually and with much effort; however, chatbot providers now offer adaptable options for a fixed monthly charge. Depending on the size of the organization, the number of chat channels, and the languages available, there is a suitable and lucrative solution for every requirement.
Around-the-clock Availability
While personal customer support hours are typically limited in the evenings, on weekends, and on public holidays, a chatbot is available 24/7. No nightly or holiday surcharges. Customers who only shop online after work in the late evening hours may ask their digital contact person inquiries. This decreases the likelihood that they may disrupt their customer journey and possibly end up with the rival.
Time Savings Through Chatbots in Retail
Chatbots perform repetitive processes, respond to frequently requested queries, and handle personal interactions with clients. Instead of wasting time answering the same questions, staff can concentrate on more sophisticated activities that require experience, expertise, and human knowledge.
In addition, there are positive client experiences, such as getting their questions answered swiftly and becoming regular customers or making recommendations.
Improving Customer Satisfaction and Customer Loyalty
Customers today have high expectations for a shop’s service. They value easy navigation to the chosen product, prompt responses to product-related concerns, and quick customer care response times. Using a chatbot, retailers can meet these expectations and even gain a significant competitive advantage.
How to Set Up AI Chatbots on Shopify and Magento
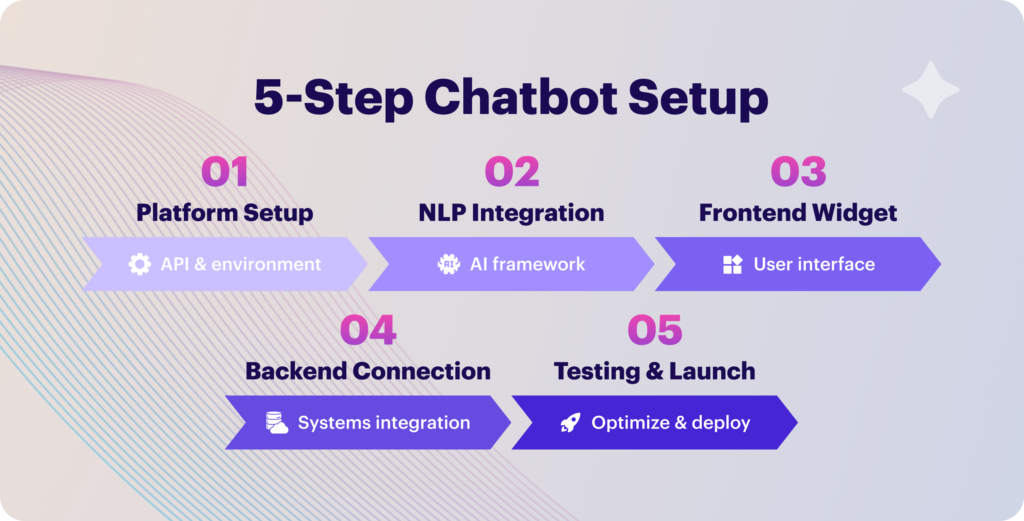
Integrating a well-designed eCommerce chatbot setup into your business can help you increase conversion rates and expedite customer assistance. Whether you’re employing a simple rule-based bot or powerful conversational AI eCommerce, adhering to best practices will help your AI assistant meet your clients’ demands while also driving income.
Step 1: Platform and Architecture Setup
Confirm your eCommerce platform version (Shopify Plus, Magento Open Source or Commerce) and the API access level required for chatbot integration. Then:
- provision a staging environment to test chatbot deployment before moving to production.
- select hosting or middleware for the chatbot backend, such as cloud functions, a Node.js server, or serverless architecture.
In the end, set up secure API keys and OAuth tokens for Shopify Admin API or Magento REST API to ensure safe communication between systems.
Step 2: Chatbot Framework and NLP Integration
Choose an AI/NLP engine (e.g., Dialogflow CX, IBM Watson Assistant, OpenAI GPT, Rasa) to drive conversational understanding. Then:
- define an intent taxonomy and entity extraction schema tailored to eCommerce scenarios like product search, order tracking, and FAQs.
- implement session management and context storage for per-user conversation history, cart state, and customer metadata.
Configure fallback and escalation flows, allowing seamless handoff to live agents when AI confidence is low.
Step 3: Frontend Integration
Embed the chatbot widget or iframe into the storefront theme (Liquid templates for Shopify, PHTML/JS for Magento). Then:
- ensure responsive design and mobile compatibility to maintain a smooth user experience.
- integrate real-time user events such as clicks, cart updates, and search queries for dynamic, context-aware responses.
And validate that context-aware responses trigger appropriately based on user action, ensuring seamless handoff to backend systems and fallback flows if needed.
Step 4: Backend and eCommerce System Integration
Connect the chatbot to the product catalog API to deliver up-to-date product recommendations. Then:
- integrate with order management systems to provide tracking and status updates.
- sync user data with CRM or marketing automation tools (e.g., Klaviyo, Salesforce, HubSpot) to enable personalized engagement.
You have to ensure secure handling of PII and compliance with GDPR/CCPA regulations.
Step 5: Testing and Optimization
Unit test all API calls and intent triggers for correctness. Then:
- perform load testing to handle concurrent user interactions.
- monitor performance metrics such as response latency, intent recognition accuracy, and fallback rates.
Run A/B tests on conversation flows to optimize engagement and conversion rates.
Best AI Chatbot Tools for eCommerce Stores
A chatbot for online stores are classified into various categories based on their complexity and capabilities:
- Rule-based chatbots, such as ManyChat, Tidio (basic workflows), and Landbot’s pre-configured bots, provide structured interactions via predefined conversation flows, making them excellent for dealing with commonly asked queries and simple customer support requests. Despite their limited flexibility, they deliver consistent responses and work well for firms with simple support requirements.
- AI-powered conversational chatbots use natural language processing and machine learning to comprehend user intent and give more dynamic responses. Platforms like Chatfuel, IBM Watson Assistant, and Drift can handle complicated queries, change responses depending on context and consumer behavior, and interact with popular eCommerce systems like Shopify, WooCommerce, and Magento.

Platforms differ primarily in terms of integration capabilities with major eCommerce systems, AI intelligence levels, price methods ranging from per-conversation to enterprise licensing, and implementation difficulty.
From personalised product suggestions and automatic order tracking to real-time lead qualification and post-purchase engagement, these solutions improve the customer experience at every touchpoint. Businesses that integrate chatbot for online stores into their Shopify or Magento stores may reduce support workloads, increase conversions, and provide a true one-on-one purchasing experience that increases loyalty and revenue.
Are you ready to boost your online store with AI-driven conversational experiences? Partner with Stellar Soft to develop intelligent chatbots tailored to your eCommerce platform, streamline AI customer service, and open up new revenue prospects. Begin creating smarter interactions today.